Classification and Tagging
Classification is the allocation of one tag from a group of possible tags to a Sintelix document.
Tagging is the assignment of zero or more tags from a group of possible tags to a Sintelix document.
These operations are very similar and their user interfaces are almost identical.
Classifiers and Taggers can be learned from training data. The training data consists of documents each marked up with tags.
Classifiers and Taggers can be assigned to Document Processing configurations so that tags can be assigned to documents as they are ingested.
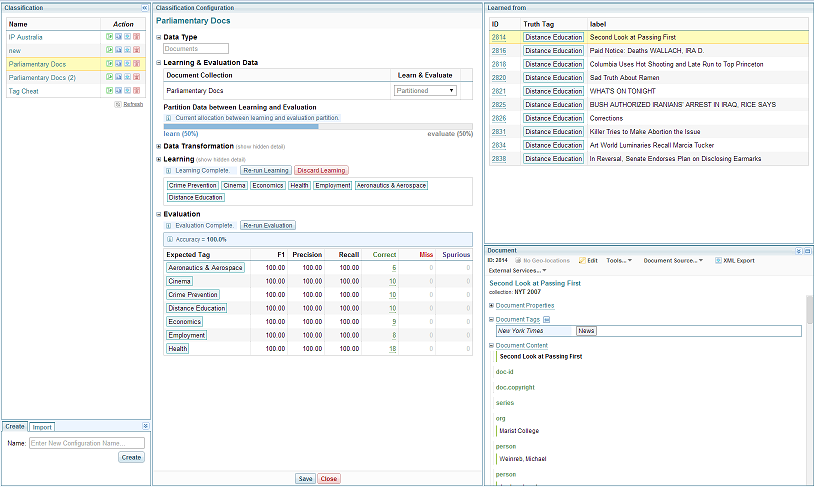
Training a classifier
To train a classifier enter the classifier's name in the Create dialog box underneath the classifier listing.
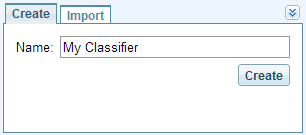
The classifier configuration pane comes up. The Data Type is fixed at "Documents".
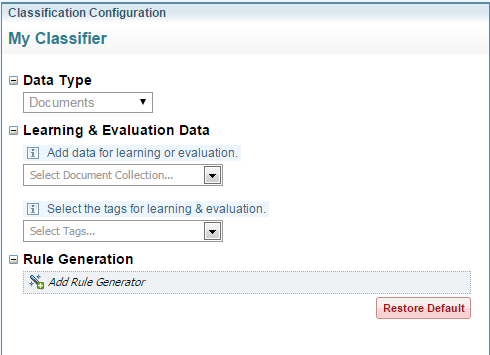
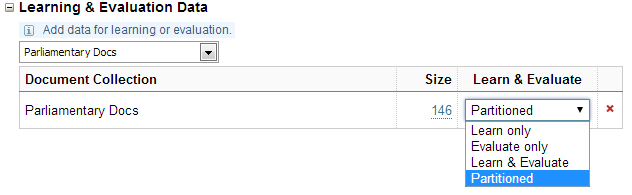
Enter one or more document collections A collection is a container for storing and organising ingested files and documents. Only the textual content is stored in collections, not the original files and documents. to learn/evaluation from (for example, "Parliamentary Docs", below):
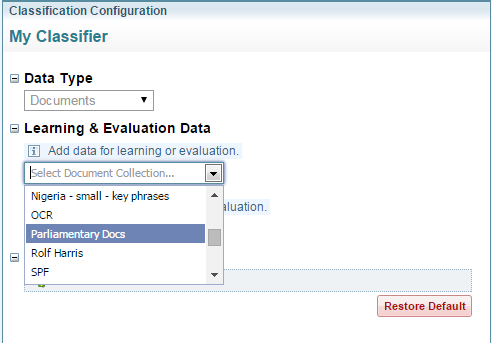
Select how the collection is to be applied to learning and/or evaluation:
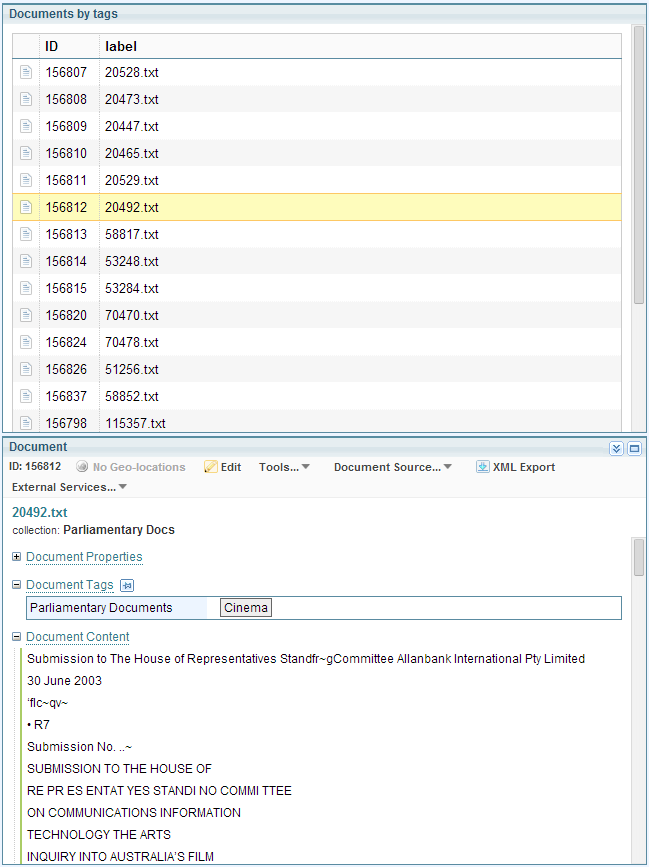
You can explore the documents of each collection by clicking on the size field in the table of document collections, which opens a new pane at the right-hand of the screen:
The documents from all the collections marked "Partitioned" are combined and then partitioned at random, subject to achieving the specified learn/evaluation split:

[You have the option of reseeding the random partition process.]
Specify the tag category to be used for classification/evaluation. It should have one and only one tag per document:
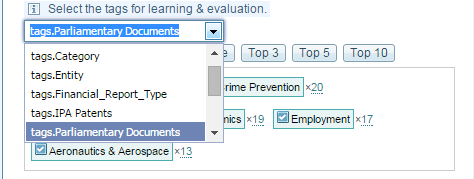
Select which of the possible tags are to be used by clicking the tick icon on the tag boxes. Documents with other tags are excluded.

You can inspect the documents of each class by clicking the frequency numbers in the tag listing.
Guidance on how to add new fields to the classifier (i.e. properties and tags) are provided in the Configuring Classification and Tagging page.
![]()
When you have completed your configuration click "Save & Learn":

If some of the data is assigned for evaluation, when training is complete the evaluation table applies.
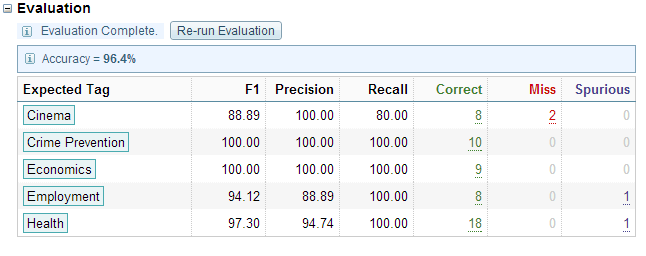
You can click the document totals in the Correct, Miss and Spurious columns to list and review the documents; for example:
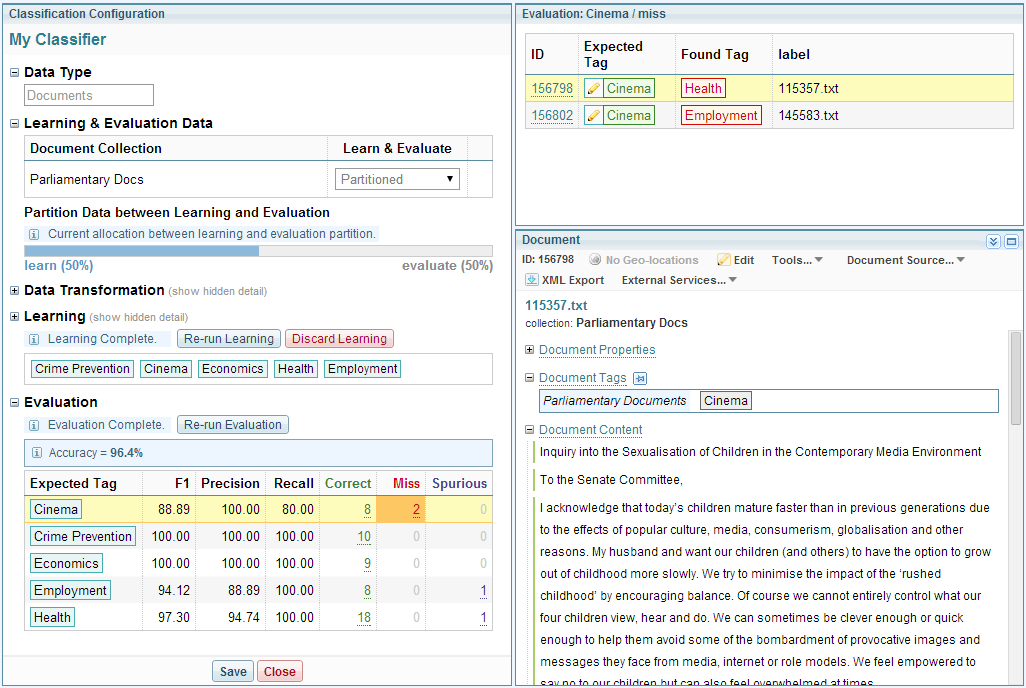
Iterative improvement
Generally, ‘gold standard’ classifications of documents are not strong and should normally be reviewed to improve classification performance.
Varying the fields used for classification can make a significant difference to performance.