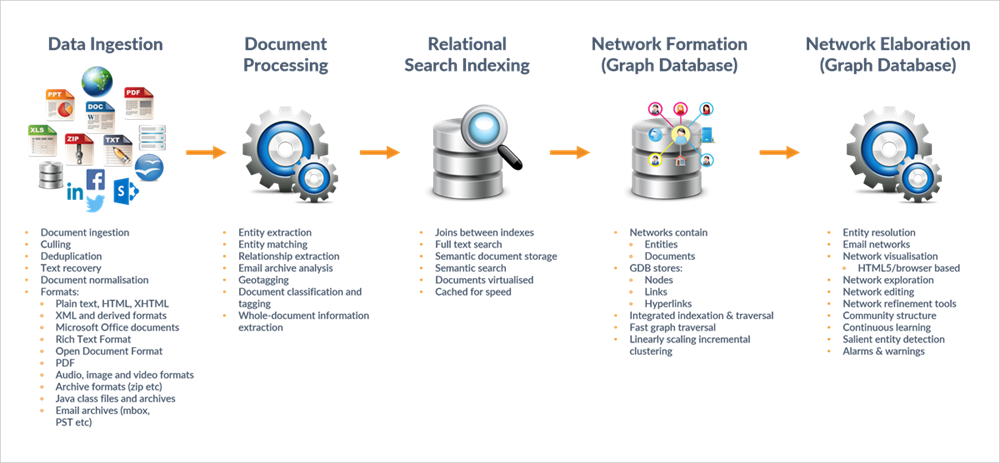
Sintelix Workflow
Sintelix’s main processing chain comprises five main elements:
- Data Ingestion: intake of data (for example, documents) from the server file system, the user’s computer or the Internet. Ingested documents are normalized to the Sintelix Document Model which can be serialized to XML and resembles XHTML in the information it can store. More than 200 common file formats are recognised, and have specific parsers.
- Document Processing: each document is individually processed. The Document Processing configuration defines the identity of each module participating in this step, and the order in which they are executed. For more information see Sintelix's document processing workflow.
- Relational Search Indexing: Sintelix is equipped with a document database that allows both table relationships and fast full text search. Documents and the accompanying entities and tags are stored in the Relational Search Engine.
- Network Formation: the base network containing nodes for entities and documents is formed from the ingested documents which are processed individually. Initially, the network is not connected across documents.
- Network Elaboration: the base network is extended by resolving entities across multiple documents, recognising email threads, detecting communities etc.