Structured Classifiers
Structured classification is an advanced and powerful type of classification that involves collaboration of multiple autoclassifiers.
A structured classifier is configured to automatically generate tags for a given taxonomy.
A taxonomy is an important asset to structured classifiers. It provides a gold standard (goal) to train and evaluate the performance of auto-classification of a structured classifier.
Autoclassifiers
An autoclassifier is created for each level (tag category) on the taxonomy and is responsible for generate classification tags for that tag category.
Develop autoclassifiers from the highest level of interest in the taxonomy down to the lowest (main output) level.
Output from one autoclassifier can be used as the input of another, forming a ‘structured’ classification workflow.
The main output classification category is generally the lowest level on the taxonomy, but it need not be the case.
Below is an example of a configured structured classifier.
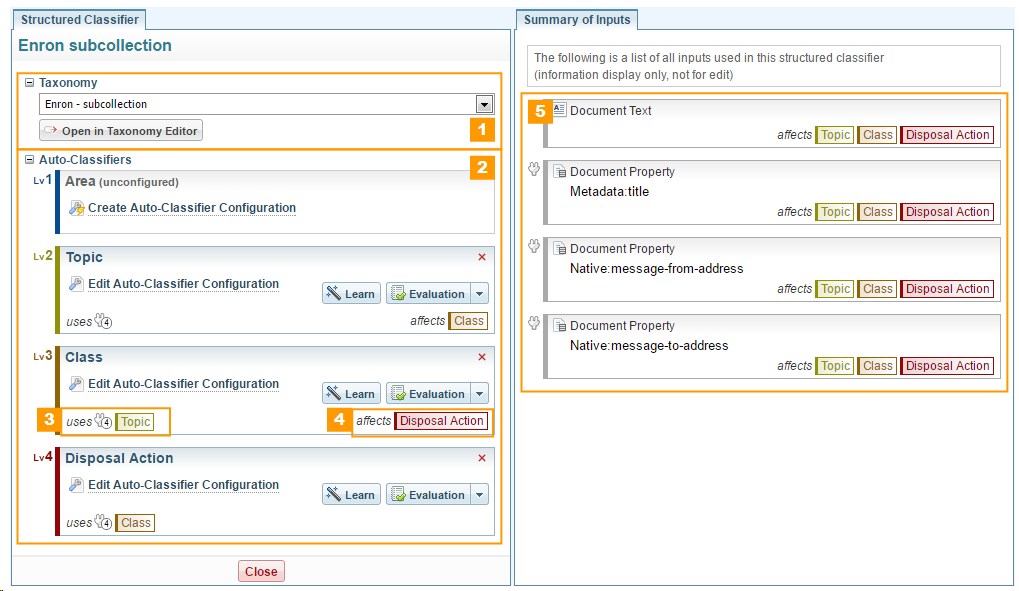
A configured structured classifier:
- The referenced taxonomy
- List of autoclassifiers in order of levels
- Inputs used by this autoclassifier (that is, its dependencies)
- Other autoclassifiers affected by its output (that is, what uses and depends on this autoclassifier)
- List of inputs from documents used by any autoclassifiers
Configure an autoclassifier
Autoclassifiers contain subclassifiers that operate in sequence, one after another; once one has captured and item of data (documents) that document is given a tag and removed from further consideration by subsequent subclassifiers.
The first stage of an autoclassifier constrains (where possible) the output of an autoclassifier to be consistent with either its parent or child nodes.
Use the learned classifiers, where possible, to do most of the work for you.
Add rule-based classifiers and search-based classifiers to remove, easily identifiable documents or groups of documents that are causing errors.
Where a learned classifier is generating errors for a class (for example, class B), place the learned classifier in the late position and remove the problem documents with appropriately generic search or rule-based classifiers put previously in the sequence.
For an non-main output level, select only those classes for output that are accurately being recognised. Subsequent autoclassifiers will then handle the data that has not been classified or is not constrained by the classes allocated to neighbouring levels.
Procedure for perfecting a structured classifier
To perfect a structured classifier:
- Set inheritance from a neighbouring level (above or below).
- Set up a learned classifier at late stage.
- Place search and rule-based stages to remove data that the learned classifier tends to spuriously assign to the wrong class before the late stage learned classifier.
- You may have to change the ‘gold standard’ to improve the operation of the structured classifier.