The Text Graph
The Text Graph is a convenient model for extracting information from continuous text. The graph for basic plain text is a one-dimensional graph, comprising a single chain of alternating nodes and links. The links represent tokens and the nodes represent the transition between tokens.
Example:
Consider the text: hello, world!
During Named Entity Extraction this text is split into four tokens:
"hello", comma, "world", exclamation mark
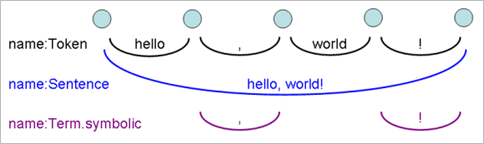
This creates a graph of five nodes and four links (each named Token) formed from these tokens:

The process of information extraction on plain text can be accommodated within a process of adding, deleting and modifying links on the graph, as below for example:
Nodes and tokens
Nodes and Tokens are the backbone of the graph. Each node is linked to its adjacent nodes by Tokens. Tokens are the most basic links in the graph. Nodes and Tokens are created automatically during document processing and cannot be added to or deleted subsequently.
Nodes contain any white space characters (spaces, carriage returns, etc.) between the Tokens. Each conventional word becomes a token. Alphanumeric sequences are divided into tokens where letter sequences join number sequences.
Like other graph elements, Nodes and Tokens also have features (see Features). These are key-value pairs that contain more information about the element's state and position.
A good way to find out the kind and subkind descriptors available is to put some text relevant to your project into the graph analyser UI, and see what is listed. In the example below, the cursor is hovering over "Term.symbolic" and the instances are shown highlighted on the text graph above.
More about links
Links can be made between any pair of nodes in the graph.
Each link contains:
- The link name. The name is permanent. No processing module can alter a link name after its creation.
- The start and end nodes of the link. These are also permanent and cannot be altered following link creation.
- Features. The features of any link can be altered by further processing.
- Text. That is the full text covered by the link excluding the text of edge nodes.
Links represent spans of text.
In EES, rules that affect links make changes to the graph immediately after the rule has fired.
The link hierarchy and implicit wildcards
Each link name is based on a hierarchical structure that includes an optional namespace.
For example; a processing module might create a link called
vehicle.car.small.
That link would have the namespace "transportation" and be of the type "vehicle.car.small".
The link can then be referred to by the following names:
*// this will match any link using the "transportation" namespace
vehicle// any link that matches both the "transportation" namespace and falls within the "vehicle" hierarchy
vehicle.car.small// the exact name of the link
Notable link hierarchies
Sintelix uses several built-in modules to create or use links under special names for specific purposes:
- Token - Links under the "Token" hierarchy form the backbone of the graph. There is always one token present between any two neighbouring nodes and this cannot be deleted. The exact name of a Token link will categorize the token by words, numbers and punctuation symbols.
- Term - Links under the "Term" hierarchy indicate popular words and short phrases such as English determinants ("the", "a", etc.), prepositions and common symbols.
- Number - various type of numbers
- lookup: - Links under the "lookup" namespace are added automatically by the Sintelix Lookup Module. This module contains a database of phrases of interest.
Entity extraction scripts as formal grammars
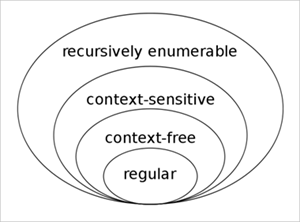
Entity extraction scripts are a scripting language based on an extended form of Context Sensitive Grammar (CSG), the third level within the Chomsky hierarchy, pictured here.