EES Basics
EES Rules and their execution
Entity Extraction Scripts (EES) are written as a sequence of rules. Each rule works on a graph (which is a sequence of nodes and links - see The Text Graph), and attempts to:
- match a sequence of graph nodes and links, and
- add or delete more links or add/modify their features.
Within each text block, rules execute in the order written, with the output of each rule available to the rules that follow. If multiple EES files are used then they are applied to each text block in the sequence they appear in the Document Processing Configuration.
Rule matching is greedy. If, starting on an arbitrary node, the same rule can be matched in several ways, the longest is chosen.
Basic syntax of EES rules
White space
All white space is considered equal. For optimum readability, use new lines, tabs and spaces to indent and align rules.
Comments
Use C++/Java comments style.
// this is a comment until end of line
/* this is a comment which can span multiple lines */Simple EES rule
Each rule has two parts:
- The matching pattern.
- One or more output phrases (statements beginning with "
>").
Matching patterns
The basic syntax for a matching pattern matches a sequence of pattern elements on the graph. Each pattern element usually matches a link. For example, a matching pattern might have three elements:
pattern_element1
pattern_element2
pattern_element3Links in a matching pattern can be listed across the page without changing the meaning:
pattern_element1 pattern_element2 pattern_element3
Example:
The token string "Paris is fun" is matched by the following sequence:
Token<string="Paris">
Token<string="is">
Token<string="fun">Pattern element conditions
Pattern elements may contain pattern element conditions, which serve to make the pattern element more selective in matching graph elements:
pattern_element1<conditions1> pattern_element2<conditions2> pattern_element3<conditions3>Conditions are expressed in relation to the features of a graph element. The conditions are contained between angled brackets ("<" and ">") and there may be several:
pattern_element<value1_left=value1_right, value2_left=value2_right, ....>Each condition takes the form of an equality or an inequality
value_left=value_rightor
value_left!=value_right...where left or right values can be constants or functions.
Output phrases - creating a link
The most common output phrase when matching a sequence is by creating a new link.
Syntax:
The syntax for link creation is:
value_left=> new_link_name<feature1=value1, feature2=value2...>The features within the angle brackets ("<>") are then added to the newly created link.
Example:
Let's look at a full EES rule for this:
Token<text()="hello">
Term.symbolic
Token<text()="world">
Term.symbolic
> Exclamation<welcome=>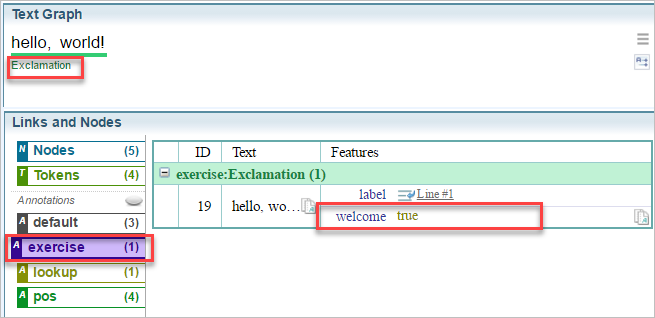
The Sintelix Text Graph view (above) shows that the link "exercise:Exclamation" has been created over the text "hello, world!" with the feature "welcome" set to "true".
If you want to see the output of your rules, use the "tag:" name space, for example:

Creating Text References in documents
To create a visible text reference, use the namespace "tag" with the output phrase.
> tag_name<...> \\ where "..." are feature settingsExample:
We have some text below:
The blue car, which was leaking oil, drove west.
We apply the following matching pattern:
Token<text()="blue">
Token<text()="car">
Term.symbolic
>tag:Blue_carThis rule will fire on the text segment "blue car" and generate a text reference with tag name "Blue_car", as shown here.

Set a Speaker
Within the output phrase use the @setspeaker command to rename the speaker channel containing the current pattern. Set the name label to a "string" value (usually the name of the entity).
> @setspeaker<name=$speaker.text()>Example:
(lookup:Person-title?
lookup:Person.name+) = $speaker
> @setspeaker<name=$speaker.text()>
> tag:SpeakerThe Text Editor
The text editor provides code highlighting.
Obtain the list of programming primitives by placing the cursor in the text area and pressing ctrl-space:
Testing and debugging Entity Extraction Scripts
The most productive method for testing EES involves using the Text Graph analyser (see Text Graph analyser and Testing scripts with the Text Graph analyser).
There are some useful capabilities described in Debugging Entity Extraction Scripts.
Including Entity Extraction Scripts in the Document Processing workflow
EES can be added into the Sintelix workflow so that they can be used to process documents in bulk.
You have the choice of two stages in the Sintelix workflow for your EES - Early and Late. Built-in learned entities (with link types such as tag:Person, tag:Organisation and tag:Location) are only available for use in matching patterns when the script is inserted for Late Stage processing.
EES are inserted into the Sintelix workflow via the Document Processing Configuration - which can be accessed via the Configuration menu or directly from the Text Graph analyser. The image below shows the document processing configuration needed to run the example EES.
EES are run over documents in the order they occur (from top to bottom) shown in the tables here.
Acronym detection is enabled only for a text references created by an EES added at the early stage. Acronyms will not be identified for text references created by a late script, therefore acronym detection also should be handled by the script.