Output Phrases
Creating a single output link
Fixed name
To create a single link on the graph, just add an output phrase of the form:
> [guard] [$segment label = ]new_link_name<feature1=value1, feature2=value2...>A very simple output phrase is used in the rule below:
Token<text()="hello">
Term.symbolic
Token<text()="world">
Term.symbolic
>Exclamation<welcome=>Variable name
There exists an alternative way of creating output links, using explicit @create action:
Token<text()="hello">
Term.symbolic
Token<text()="world">
Term.symbolic
> @create<ns="tag", name="Exclamation"> <welcome=true>The advantage of @create action is that parameters "ns" and "name" can be calculated using functions, thus potentially creating variable link names. If the calculated value for "name" is invalid (such as null) the output is not created.
Multiple output phrases in one rule
Each EES rule can create several links on the text graph. The code pattern involves inserting multiple output ">"s after a rule. The span of each output is controlled by matching segment labels.
Example:
This example shows the recognition of a pattern that creates three output links. All of them are in the "tag" namespace so you can see the output in the ordinary document visualiser.
Token<text()="30">
Token<text()=")">
(Number.integer.lexical
lookup:Date.month
Token.punctuation.comma
Token.number.4-digit) = $32_Filing_Date
Token.word.non-letter = $33_IP_Office
Token* = $31_Priority_Number
>$32_Filing_Date = "tag:Filing Date"<value=$32_Filing_Date.text()>
>$33_IP_Office = "tag:IP Office"<value=$33_IP_Office.text()>
>$31_Priority_Number = "tag:Priority Number"<value=$31_Priority_Number.text()>

Nested output links
Example:
This example shows that segment labels can be nested:
Token<text()="30">
Token<text()=")">
((Number.integer.lexical
lookup:Date.month
Token.punctuation.comma
Token.number.4-digit) = $32_Filing_Date
Token.word.non-letter = $33_IP_Office) = $big
Token* = $31_Priority_Number
>$32_Filing_Date = "tag:Filing Date"<value=$32_Filing_Date.text()>
>$33_IP_Office = "tag:IP Office"<value=$33_IP_Office.text()>
>$31_Priority_Number = "tag:Priority Number"<value=$31_Priority_Number.text()>
>$big = tag:big

When outputting overlapping links if they are in the "tag:" namespace, the link with the longest span wins. For other namespaces, no such deletion occurs.
Modifying link features
Sometimes you will want to modify the features of matched links without creating any new links.
Syntax:
> $label<feature1=value1, feature2=value2,...>Example:
//find the left half and then the right half. Add the feature "has_right" to the left half and then "has_left" to the right half; if such a sequence can be found.
exercise:left_half = $left
exercise:right_half = $right
> $left<has_right=true>
> $right<has_left=true>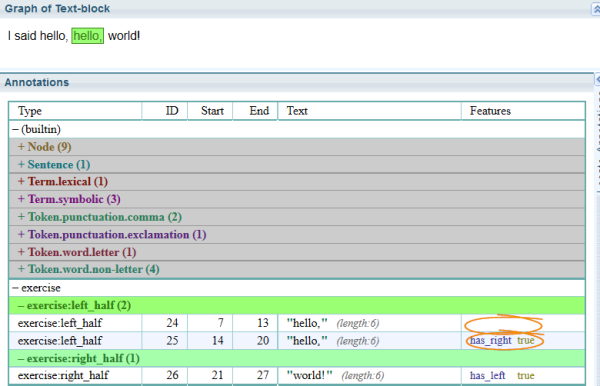
To copy all modifiable features from one or more links in the matching pattern to an output link see Wildcard Feature Transfer to Output Links.
The null action
Sometimes you will want to match a sequence of links simply to delete them and you won't need to create new links. In this case you use the syntax shown here.
Syntax:
> -Example:
//find the left half followed by the right half and then delete the matching halves.
(
exercise:left_half
exercise:right_half
) = $delete
> -Deleting links
You can delete any link except those of type Token.
To delete all non-Token links matching pattern elements within a labelled pattern segment, use a label starting with the text "$delete" (for example, "$deleteExample" or simply "$delete").
Deletion takes place after the output phrases have been executed, so you can refer to deleted pattern elements in output phrases.
Example:
//find the word "hello" with an optional comma. Then make a new link "left_half".
Token<text()r="hello">
Term.symbolic ?
> exercise:left_half
//find the phrase "world!". Then make a new link "right_half".
Token<text()="world">
Term.symbolic
> exercise:right_half
//Now find the left_half and the right_half. Delete both halves and make a new link "two halves".
(
exercise:left_half
exercise:right_half
) = $delete
> exercise:two_halves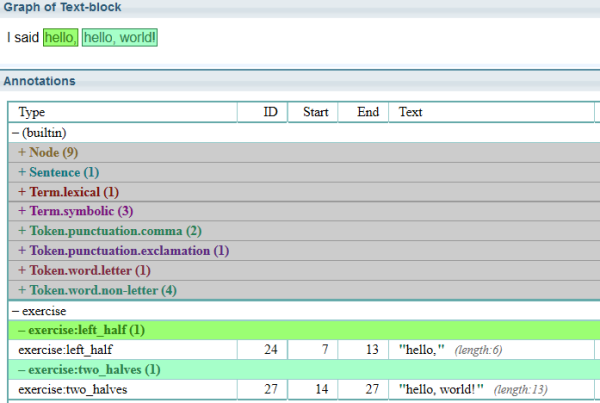
So in this example there were two "left_half" links created for two "hello" phrases identified. There was one "right_half" link created for one "world!" phrase. Once the "two_halves" rule deleted the inputs there is only one "left_half" link remaining.
Limiting the match to the interior of another link
You can constrain the matching pattern to operate only within the span of another link.
This is useful when you can detect the approximate area where the information you want to extract is located. You can then write simpler matching patterns that operate only within that area as they do not need to reject all the text outside the spanning link.
Syntax:
> !!another_link_name new_link_name<feature1=value1, feature2=value2, ...> //only matches within a linkExample:
//To create Exclamation link
Token<text()="hello">
Term.symbolic
Token<text()="world">
Term.symbolic
> exercise:Exclamation
//to find a token "hello" only within Exclamation
Token<text()="hello">
>!!exercise:Exclamation
exercise:HelloWithin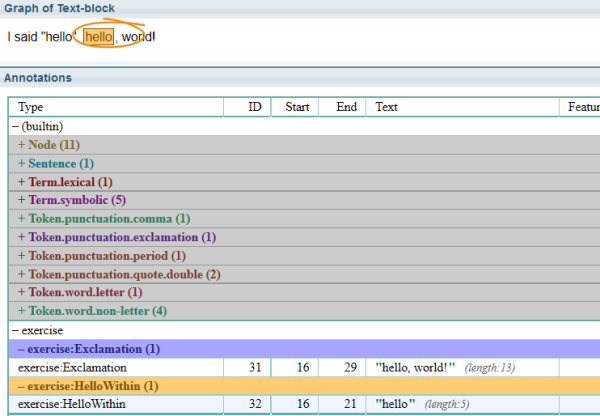
Any matches that fall partially within the defined area and partially without the defined area will not be reported.
Limiting the match to the exterior of another link
You can execute matching logic fully outside another link.
Syntax:
> !another_link_name new_link_name<feature1=value1, feature2=value2, ...> //only matches outside a linkExample:
//To create Exclamation link
Token<text()="hello">
Term.symbolic
Token<text()="world">
Term.symbolic
> exercise:Exclamation
//to find a token "hello" only external to Exclamation
Token<text()="hello">
>!exercise:Exclamation
exercise:HelloOutside
Any matches that fall partially within the defined area and partially without the defined area will not be reported.