EES Functions
Functions used for matching
Up to this point, we have focused on Matching Patterns where the conditions rely on features, which are values attached to links and nodes, for example using the feature, length, as in Token<length=5>.
In Pattern Element Conditions we began to use functions to provide more sophisticated matching patterns.
Functions can perform complex operations on the following argument types:
- features
- position or other properties of a matched sequence or
- position or other properties of a labelled pattern segment.
Example: Performing an arithmetic operation on a feature
Tokens have the feature "length" which is the number of characters of the token.
Token<ge(length,10)=true> //matches any token that has a length greater than or equal to 10The feature "length" is passed to the function "ge" along with the literal value of 10. This will return either a false or a true result which is then compared with the literal "true" to verify the match.
Example: Nested functions
Sentence<ge(clength(), 10) = true> //match any sentence whose length (in characters) is greater than or equal to 10Here the link "Sentence" does not have a "length" feature. However, you can use a function clength() to calculate the character length of the link. This calculated value can then be passed to the ge() function.
Example: Referring to another label
When you match one link - the default context of any function is the link that is being matched. However, it is possible to use a label to modify that context:
//match the shorter sentence followed by the longer sentence
Sentence = $sentence1
Sentence<ge(clength(), $sentence1.clength()) = true>
> exercise:two_sentencesHere the condition for matching the second link involves calling "clength" twice: once on the current link, and once on the link referred to by $sentence1.
Functions used when creating new links
You can use the functions that are used in matching to create new feature values:
//match the shorter sentence followed by the longer sentence
Sentence = $sentence1
Sentence<ge(clength(), $sentence1.clength()) = true> = $sentence2
> exercise:two_sentences<firstLength=sentence1.clength(), secondLength=sentence2.clength()>Binding functions to arguments
Functions are bound to their arguments either explicitly or contextually.
Explicit binding
Explicit bindings take the following forms:
Argument form :
function_name(list_of_arguments) // arguments may be constants, labelled pattern segments, other expressionsFor example,
float($my_segment.length)Dot form :
$labelled_pattern_segment.function_name() // applied to labelled pattern segmentsFor example,
Token{2} = $person
Token.punctuation.comma
Token{3} = $code
>Person_Location<name = $person.text(), my_code = $code.cat()>Contextual binding
Contextual binding is available in Matching Pattern Segments and in Output Phrases. The contextual (default) argument for Matching Pattern Segments is the segment itself. the contextual (default) argument for Output Phrases is link being created by the output phrase.
Token<gt(tlength(),5)=false> // Matching Pattern Element - "tlength" is applied to "Token"
>link_name<out_text = text()> // Output Phrase - "text" is applied to the output link with name link_name An example involving both types of contextual binding:
Token=$label1
Token<text()=$label1.text()> //text() operates on a previously matched annotation as indicated by the label
> double_token<myCreatedLinkLength=clength()> //clength() operates on the output phraseFunction reference
Explicitly bound functions
The variable types of the arguments are nominal, if type errors are made default behaviour is designed to give safe results.
|
Function Name |
Arguments/Binding |
Description |
Example |
|
Single argument numerical functions |
|||
|
int |
one argument |
argument converted to an integer, or null if conversion failed |
int("45") [=45] |
|
long |
one argument |
argument converted to a long integer, or null if conversion failed |
long("45")[=45] |
|
num |
one argument |
argument converted to an integer, or if that fails converted to a long, or if that fails converted to a double, or null if the above all fail |
num("1e3") [=1000.0] num("1000")[=1000] |
|
float |
one argument |
argument converted to a float value, or null if conversion failed |
float("10")[=10.0] |
|
double |
one argument |
argument converted to a double value, or null if conversion failed |
double("10")[=10.0] |
|
sign |
one numerical argument |
1 if argument is positive, 0 if zero, -1 if negative, NaN if not numeric |
sign(-4)[=-1] |
|
neg |
one numerical argument |
negative value of numeric argument, or NaN is the argument is not numeric |
neg(13)[=-13] |
|
abs |
one numerical argument |
absolute value of numeric argument, or NaN is the argument is not numeric |
abs(-9.0)[=9.0] |
|
Multiple argument functions |
|||
|
add |
any number of numerical arguments |
sum of all arguments, or NaN if one of them was not numeric |
add(5,3,2)[=10] |
|
sub |
two numerical arguments |
second argument subtracted from first, or NaN if one of them was not numeric |
sub(3,7)[=-4] |
|
mult |
any number of numerical arguments |
product of all arguments, or NaN if one of them was not numeric |
mult(2,4,3)[=24] |
|
zmult |
any number of numerical arguments |
product of all arguments, or zero if one of them is null, or NaN if one of them was not numeric |
zmult(2,"string",3)[=NaN] |
|
div |
two numerical arguments |
quotient of two numbers, or NaN if one of them is not numeric |
div(3,2)[=1.5] |
|
or |
any number of Boolean arguments |
if all arguments are Boolean, logical OR of all arguments. If all arguments are Integer, binary OR of all arguments. Otherwise null. |
or(true,true)[=true] |
|
and |
any number of Boolean arguments |
if all arguments are Boolean, logical AND of all arguments. If all arguments are Integer, binary AND of all arguments. Otherwise null. |
and(true,false)[=false] |
|
max |
any number of numerical arguments |
largest numeric argument, or NaN if one of them is not numeric |
max(1,2,3)[=3] |
|
min |
any number of numerical arguments |
smallest numeric argument, or NaN if one of them is not numeric |
min(1,2,3)[=1] |
|
mod |
two numerical arguments |
reminder of division between two arguments, or NaN if one of them is not numeric |
mod(5,3)[=2] |
|
unify |
any number of numerical arguments |
if all arguments are equal, the single value they're equal to. Otherwise null. |
unify(3.0,3)[=null] |
|
range |
three arguments: val, min, max |
true if min <= val <= max, false if val is outside that range, null if any argument is not numeric |
range(2,1,3)[=true] |
|
gt |
two numerical arguments: val, min |
true if val > min, false if val <= min, null if any argument is not numeric |
gt(5,3)[=true] |
|
ge |
two numerical arguments: val, min |
true if val >= min, false if val < min, null if any argument is not numeric |
ge(5,5)[=true] |
|
lt |
two numerical arguments: val, max |
true if val < max, false if val >= min, null if any argument is not numeric |
lt(3,4)[=true] |
|
le |
two numerical arguments: val, max |
true if val <= max, false if val > min, null if any argument is not numeric |
le(3,3)[=true] |
|
if |
two arguments: if, then; or three arguments: if, then, else |
if "if" value is Boolean and is true, returns value of "then". Otherwise returns value of "else" or null if "else" is not present |
if(le(3,3),5,4)[=5] |
|
not |
one Boolean argument |
negates the input |
not(false) [=true] |
Text functions - various bindings
|
Function Name |
Inputs/Binding |
Description and examples |
|---|---|---|
|
Text functions |
||
|
text |
contextual or multiple explicit arguments |
text of current context, joined by space if current label was matched many times; or text of all arguments joined by space. Matching pattern example: Token<text()="John"> //matches the word "John" Output phrase feature example: out_text=text($location.text(),"-",$person.text()) //output phrase |
| textlower | contextual |
text of current context in lower case. Matching pattern example: Token<textlower()="john"> //matches only lower case "john" Output phrase feature example: feature=$location.textlower() //output phrase |
| textupper | contextual |
text of current context in upper case. Matching pattern example: Token<textupper()="JOHN"> //matches only upper case "JOHN" Output phrase feature example: feature=$location.textupper() //output phrase |
|
cat |
contextual or multiple explicit arguments |
text of current context, joined together if current label was matched many times; or text of all arguments joined together. out_text=cat($location.text(),", ",$person.text()) |
| texts | contextual |
(multi-value) text values of all matches of current context (identified by its label) (Token = $token){5} This example concatenates all the texts of five tokens. |
|
values |
contextual and one argument |
(multi-value) all values of the feature identified by argument within its label (Token = $token){5} This example adds together all the lengths of five tokens. |
|
startswith |
two arguments |
true if second argument is a string or character that's a prefix of first argument. Otherwise false. startswith("Paris in the Spring", "Paris") // [=true] |
|
endswith |
two arguments |
true if second argument is a string or character that's a suffix of first argument. Otherwise false. endswith("Paris in the Spring", "Spring") // [=true] |
|
match |
two or more arguments |
true if first argument is equal to any of the following arguments, false if it's not equal to any of them. null if first argument is null. match("book", "car", "book", "letter") // [=true] |
|
pattern |
two arguments |
true if a standard Java regular expression described by second argument matches string from first argument. Returns false if any argument is not a string pattern("XXXXO","X*O") // [=true] |
Text conversion functions
|
Function Name |
Inputs |
Description and examples |
|---|---|---|
|
Text functions |
||
|
lower |
one argument |
argument converted to lower case string lower($label1.text()) |
|
upper |
one argument |
argument converted to upper case string upper($label2.cat()) |
| replace | three arguments |
argument 1 with every substring equal to argument 2 replaced with argument 3 replace("One Two Three Two One","Two","2") // [="One 2 Three 2 One"] |
| replaceChars | three arguments |
argument 1 with every character from argument 2 replaced with corresponding character from argument 3. If argument 3 doesn't have a corresponding character (is too short), character is removed. replaceChars("abcda","b","z") // [="azcda"] ('b' becomes 'z') replaceChars("abcda","ab","yz") // [="yzcdy"] ('a' becomes 'y', 'b' becomes 'z') replaceChars("abcda","ab","y") // [="ycdy"] ('a' becomes 'y', 'b' gets removed) replaceChars("abcda","ab","") // [="cd"] ('a' and 'b' gets removed) |
| capitalise | one argument |
argument converted to capitalised form capitalise("dog") // [="Dog"] capitalise("DOG") // [="Dog"] capitalise("brown dog") // [="Brown dog"] |
| capitaliseWords | one argument |
all words of argument converted to capitalised form capitaliseWords("brown DOG") // [="Brown Dog"] |
| stripLeft | two arguments |
strips any of argument 2's characters from the beginning of argument 1. If argument 2 is null, all whitespace is stripped stripLeft("3221 code 3221", "123 ") // [="code 3221"] stripLeft(" code 3221", null) // [="code 3221"] |
| stripRight | two arguments |
strips any of argument 2's characters from the end of argument 1. If argument 2 is null, all whitespace is stripped stripRight("120.00", "0.") // [="12"] |
| trim | one argument |
removes leading and trailing whitespace from argument 1 trim("dog ") // [="dog"] |
| normalize | one argument |
removes leading and trailing whitespace, then replaces consecutive whitespace characters with a space normalize(" brown dog ") // [="brown dog"] |
Contextually bound functions
|
Function Name |
Inputs/Binding |
Description and example |
|---|---|---|
|
Pattern Matching Functions |
||
|
costarts |
current context and optionally further pairs of arguments in the form "feature name" (as a string) followed by expected feature value. |
true if the left node of current context (current link or region indicated by label) is also a starting node of arbitrary link identified in first argument. If optional argument pairs are present, only links with matching features qualify. Text: "John Smith visited Paris" Matches two-token Persons. |
|
coends |
current context and optionally further pairs of arguments in the form "feature name" (as a string) followed by expected feature value. |
true if the right node of current context (current link or region indicated by label) is also an ending node of arbitrary link identified in first argument. If optional argument pairs are present, only links with matching features qualify. (see above) |
|
contains |
current context and optionally further pairs of arguments in the form "feature name" (as a string) followed by expected feature value. |
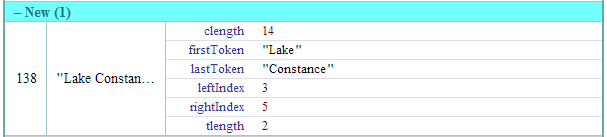
true if anywhere between current context's left and right node there exists an arbitrary link identified in first argument. If optional argument pairs are present, only links with matching features qualify. Text: "John Smith visited Lake Constance" |
|
coexists |
current context and optionally further pairs of arguments in the form "feature name" (as a string) followed by expected feature value. |
true if exactly between current context's left and right node there exists an arbitrary link identified in first argument. If optional argument pairs are present, only links with matching features qualify. Text: "John Smith visited Paris" |
|
Token sequence navigation functions |
||
|
clength |
current context |
number of characters within current context |
|
Text: "John Smith visited Paris"
|
||
|
tlength |
current context |
number of tokens within current context (see above example) |
|
firstToken |
current context |
returns text of the very first token of current context (see above example) |
|
lastToken |
current context |
returns text of the very last token of current context (see above example) |
|
leftIndex |
current context |
index of the left node of current context in its text graph (see above example) |
|
rightIndex |
current context |
index of the right node of current context in its text graph (see above example) |
DateTime function
|
Function Name |
Inputs/Binding |
Description and example |
|---|---|---|
|
datetime |
year, month, day, hour, minute, second, time zone offset in hours, time zone name. Year, month and day are required for the function to succeed. Hour has to be in 24-hour clock. |
Creates a date-time feature from components. datetime( |