Ingestion
Introduction
The ingestion configuration manages what happens to documents, files, URLs, and their textual content after the data is uploaded to Sintelix.
The Ingestion configuration also assigns other configurations to ingestion processing, including:
- Document Processing, which also links to other configurations:
- Dictionaries
- Entity Extraction Scripts
- Document Processing Scripts
- PDF Form Extractors (when licensed)
- Ontologies, which uses Icon Sets
- Classification
- Tagging
- Structured Classifiers, and
- Network Creation.
Process
To configure Ingestion:
-
Select Configurations > Ingestion
-
Select the configuration you want to modify.
See Manage Configurations for information on creating, copying, renaming, importing, exporting and deleting configurations.
-
Complete or modify each section's settings, as described below.
-
Select the button.
Document Pre-processing
Optical Character Recognition (OCR) Processing
Allows you to enable and choose settings for Optical Character Recognition (OCR) Processing to convert images and scanned documents into text.
Configure OCR
If Sintelix is connected to:
- no OCR server, the OCR options will be greyed out or the Optical Character Recognition Processing section will be unavailable. See Connect OCR.
- Sintelix OCR server, all OCR options will be available.
- ABBYY FineReader OCR server, only the first three OCR options will be available - the remainder will be greyed out.
Enable OCR by choosing one or more of the following options:
- Perform OCR processing on PDF files
- Perform OCR processing on Images files
- Perform OCR processing on images embedded in other documents
Select the required OCR processing options:
| Correct page skew | Correct for any rotation that occurred during scanning |
| Correct page geometry | Correct for any warping or distortion that occurred during scanning |
| Perform Fast Mode | Choose faster processing |
| Extract text only | Ignores images or other non-text elements. |
| Perform aggressive table detection | Applies additional processing algorithms to determine if text is organised in a table format, to recognise and extract the individual cells of a table, including column and row headings. |
| Specify type of field marking for documents with forms | If a document is a form, you can choose to how fields are marked up in documents. |
| Language | You can allow Sintelix to automatically detect the language or choose the language. |
|
Forbidden Characters |
Enter characters you do not want to be extracted, for example special characters. |
Audio and Video Processing
Enables Sintelix to transcribe audio and video files into text.
Configure Audio and Video Processing
Select the required options:
-
Enable audio and video files to be played in Sintelix.
The Unavailable message -
 - indicates that the connection to media processing server is not set up. See Audio-Video Transcription for information about connecting this capability.
- indicates that the connection to media processing server is not set up. See Audio-Video Transcription for information about connecting this capability. - Enable transcripts to be generated - to convert the audio/video to text.
-
Select transcript language code. Click the lightbulb
 and select the language required for transcription.
and select the language required for transcription.
-
Select speaker recognition mode. When this option is selected, each Speaker (person talking) will be identified. Select the required option from the dropdown:
- None (default)
- Voice
- Channel
- Voice and Channel
-
Additional vocabulary dictionaries
When transcribing audio/video files using industry-specific terminology, the accuracy of the transcription can be improved by including a dictionary of terms. For example, when lots of abbreviations are used or specialist wording used.
- From the drop-down select Additional vocabulary dictionaries based on the context of the audio/video files being transcribed. You can add multiple dictionaries.
-
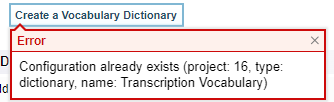
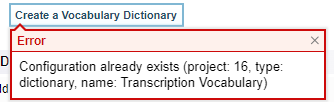
Select Create a Vocabulary Dictionary to create and open a sample dictionary called Transcription Vocabulary. See Dictionaries for more information on creating and editing dictionaries.
If there is already a dictionary created, you will get this error:
Document parsing exclusions
This option allows you to ingest files with a specific content type as a plain text source. For example, when the text/html content type is added, ingested web pages would display its full raw HTML markup, and not the parsed HTML content.
Configure Document parsing exclusions
Content Types
Below are a few examples of content types, and the types of files that normally use them:
- text/html - HTML documents and web pages.
- application/xml - XML documents and pages.
- message/rfc822 - Email messages.
- text/csv - spreadsheet.
- application/json - data format.
You can add the content types in two ways:
-
selecting the Add Content-Type option
 to add each content type individually, or
to add each content type individually, or -
selecting the Edit All option
 to enter multiple content types.
to enter multiple content types.
Add Content-Type
To add the content types individually:
-
Click on the Add content-type option -
Result: An empty field is displayed.
-
Click the lightbulb
and select the content type required. -
Repeat the above steps until all content types have been added.
-
Click the red x icon
 to remove any unwanted option.
to remove any unwanted option.
Edit All
To add the content types all at once:
-
Click on the Edit All option -
Result: A dialog box is displayed.
-
Enter each content-type on a line.
Warning: This method does not check for incorrect or misspelt entries.
-
Select OK.
Result: The entered options are updated on screen.
HTML Cleaning
When HTML cleaning is selected, non-content related and hidden elements in web pages, such as unwanted social media links, ads and navigation links, will automatically be detected and removed. This is particularly useful for extracting only the content of a news or blog article, for example.
Enable HTML Cleaning
When HTML cleaning is enabled, non-content related and hidden elements in web pages, such as unwanted social media links, ads and navigation links, will automatically be detected and removed. This is particularly useful for extracting only the content of a news or blog article, for example.

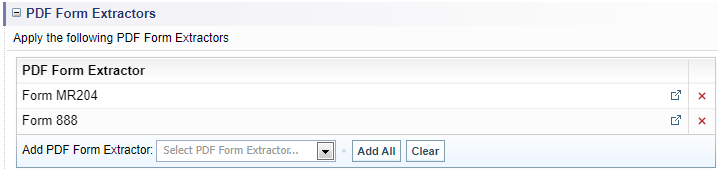
PDF Form Extractors
You can choose which PDF Form Extractor Configurations to include in this ingestion. PDF form Extractor configurations define how PDF form fields are identified, extracted and marked up.
The PDF Form Extractors option is only visible if active on the user license.
Configure PDF Form Extractors
To include PDF Form Extractor configurations:
-
select the Add PDF Form Extractor dropdown and select the required configuration,
or -
select the button to include all configurations
-
click the red x icon
to remove any unwanted configuration or select the button to remove all configurations. -
select the open icon
 to view the selected configuration in another window.
to view the selected configuration in another window.
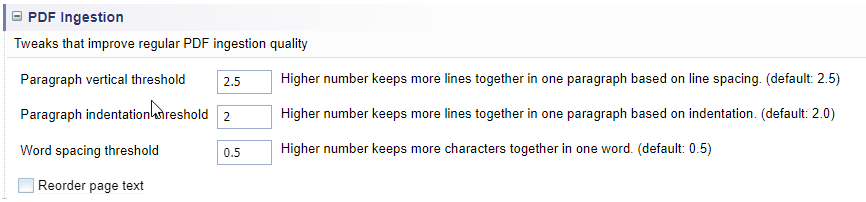
PDF Ingestion
Configure settings that improve the quality of regular PDF ingestion.
Configure PDF Ingestion
Adjust the settings, as required.
Content Generation
Creates additional content in a text block at the beginning of an ingested document. The content can be created from document properties or XML elements.
Generate Content from Document Properties
To create content from document properties, select the Add (Content Generation Rule)  button to add a row and complete the required fields.
button to add a row and complete the required fields.
| Category |
Click the lightbulb
|
| Name |
Click the lightbulb The options displayed vary depending on what Category is selected and what properties or data are available. You can use a wildcard to include multiple properties with similar names. For example, Harvest* will include all data with a name starting with Harvest, such as HarvestType and Harvester Rule Set. |
| Content in Output |
Choose to include either:
|
| Enabled | Select the checkbox to either enable or disable the content. |
|
(Remove ) |
Select the remove icon to remove an content option. |
Example of Configuration

Example of Generated Content
Below is an example of content generated from document properties and inserted at the top of the document content.

Generate from XML Elements
XML documents are processed into documents during ingestion. However, if the XML file is unrecognised, the document can be created using the XML elements to create text blocks.
Select the checkbox to enable this capability.
Storage Options
Document Deduplication
Removes duplicate (identical) documents. Does not remove different versions of the same document. For example, if there are minor variations between documents, the documents will be ingested.
Enable Document Deduplication
Select the checkbox to enable document deduplication.

Storage rules
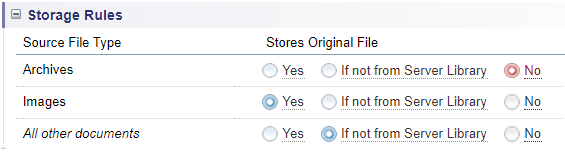
Allows you to choose the types of source documents are stored in Sintelix: archives (e.g. zip files), images and all other documents.
Storage rules
Choose which source files are stored in Sintelix.
- Yes - stores the original source file in Sintelix.
- If not from Server Library - stores the original source file in Sintelix only if it is not available in the Server Library.
- No - will not store the original source file.
Archive Handling
Creates a list of files contained in a zip archive file and stores it in Sintelix.
Configure Archive Handling
Select the checkbox to create a manifest for archive (zip) files, if any are detected and ingested.

Failure Handling
When ingesting files, if a file fails to be processed, Sintelix does not save the document to the Collection. With Failure Handling enabled, documents that fail processing are saved to the Collection with the ingestion property "is_failed" set to true. This allows users to find and inspect failed documents.
Enable Failure Handling
Select the checkbox to enable failure handling.

Document Ingestion Stages
Ingestion rules are used to decide what should be done to a document depending on the characteristics of a document. There can be more than one rule, and the order of the rules is important, as the first matched rule is applied for a document.
Language detection
Choose the language to apply to the ingested documents. The default is Auto Detect.
Configure language detection
You can either leave the default or specify the language you want detected.
Click the lightbulb ![]() and select the language required.
and select the language required.
The languages available depend on the language plugins installed with Sintelix, which you can view by selecting the Status tab. The languages with a green tick are available.
Document classifiers
Choose the Classification configurations to apply during Ingestion, if required.
Configure Document classifiers
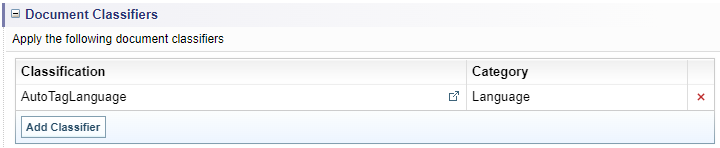
To include Classification configurations in the ingestion process:
-
select the button.
Result: The Add Classifier dialog is displayed.

-
Select the required Classifier configuration from the dropdown.
Result: The Category field is automatically completed.
-
If required, click the lightbulb
in the Category field to change the selection. -
Select the button.
Result: The selected configuration is added to the Document Classifiers list.
-
If required, select the open icon
to view the selected configuration in another window. -
If required, click the red x icon
to remove any unwanted configuration.
Document taggers
Choose the Tagging configurations to apply during Ingestion, if required.
Configure Document taggers
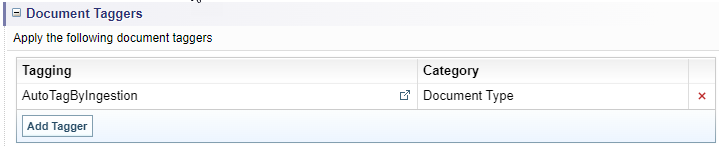
To include Tagging configurations in the ingestion process:
-
Select the button.
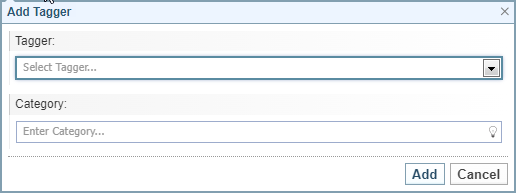
Result: The Add Tagger dialog is displayed.
-
Select the required Tagging configuration from the dropdown.
Result: The Category field is automatically completed.
-
If required, click the lightbulb
in the Category field to change the selection. -
Select the button.
Result: The selected configuration is added to the Document Taggers list.
-
If required, select the open icon
to view the selected configuration in another window. -
If required, click the red x icon
to remove any unwanted configuration.
Pre-processing
You can choose actions to apply to documents during Ingestion before the Document Processing. For example, if a Document Property is present then create a Document Tag.
Configure pre-processing
You can check for when a condition applies to a document and then select the action required, as defined in the table below.
|
When (condition applies) |
Take an action |
|---|---|
|
|
Procedure
To configure a pre-processing action:
-
Select the button.
Result: A new row is added.
-
Click on the When dropdown, choose the required condition and complete the fields displayed (click on the link to view more detailed help).
-
Click on the Action dropdown, choose the required action and complete the fields displayed.
-
The actions are carried out in sequence, so the order of the rules is important. You can use the move up
 and down
and down  arrows the change the order of the rules.
arrows the change the order of the rules. -
Select the Stop further pre-processing checkbox when you don't want any further actions carried out on the documents matching the current condition.
Example
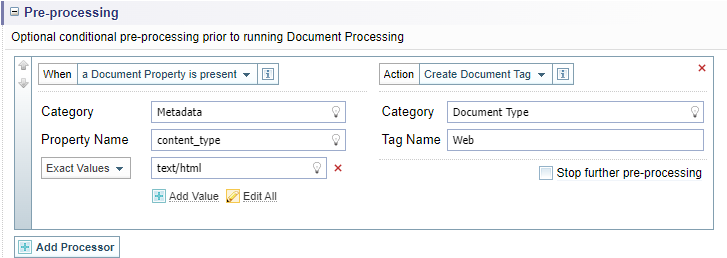
See Ingestion Report Example for an example of combining Pre-processing and Document processing configuration settings.
Ontology
Select the dropdown arrow to select an ontology to be used for document processing. Extracted text references can be turned into entities by placing a text reference’s class under Entity Classes in the selected ontology.
Document processing
Allows you to select the Document Processing configuration to apply during Ingestion. You can create rules to apply different Document Processing Configurations based on document characteristics, such as tags and metadata. If no rules have been created, or no rules match a document, the default processing rule action will be applied.
Configure document processing
You can choose to:
-
apply the Default Processing Rule only or
-
add Custom Document Processing Rules to apply before the Default Processing Rule.
Conditions and Actions
You can set conditional rules for documents and then select the action required for documents matching the rule, as defined in the table below.
|
When (condition applies) |
Take an action |
|---|---|
|
|
Procedure
To configure a document processing action:
-
Select the button.
Result: A new row is added.
-
Click on the When dropdown, choose the required condition and complete the fields displayed.
-
Click on the Action dropdown and choose the required action.
-
If the action Extract Metadata, Text and Entities is selected, the Document Processing dropdown is displayed. Select the Document Processing configuration you want to apply to documents matching the When condition.
-
The actions are carried out in sequence, so the order of the rules is important. You can use the move up
and down arrows the change the order of the rules.
Example
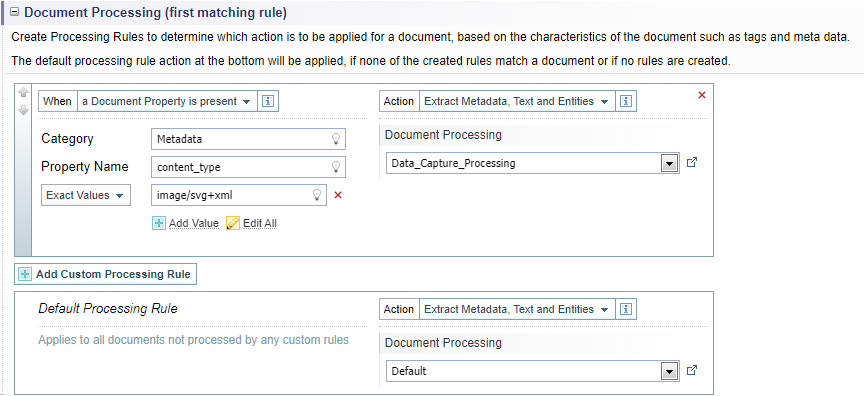
See Ingestion Report Example for an example of combining Pre-processing and Document processing configuration settings.
Structured classifiers
Choose Structured Classifiers configurations to the document ingestion process, if required.
Configure Structured Classifiers
To include Structured Classifier configurations:
-
select the Add Classifier dropdown and select the required configuration,
or -
select the button to include all configurations
-
click the red x icon
to remove any unwanted configuration or select the button to remove all configurations. -
select the open icon
to view the selected configuration in another window.
Network update configuration
The network update configuration is used to automatically generate or update a network every time a collection is processed. More than one network can be updated through this setting.
Configure Network Update

To include Network Creation configurations in the ingestion process:
-
Select the button.
Result: The Add Network Update dialog is displayed.
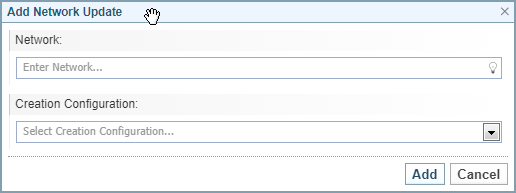
-
Select the Network you want to generate or update from the dropdown.
-
Click the lightbulb
in the Creation Configuration field to select the Network Creation configuration required. -
Select the button.
Result: The Network Update is added to the list.
-
If required, select the open icon
to view the selected configuration in another window. -
If required, click the red x icon
to remove any unwanted configuration.
Document persistence
By default, ingested documents are stored in a Collection and the entities and links extracted from these documents are stored in a Network (when a Network Update Configuration is included in Ingestion). This allows you to view and modify the documents from which the entities and links were extracted.
However, you can choose not to keep the documents in a Collection and only keep the entities and links extracted from the documents in the Network.
This does not affect existing documents in the Collection.
For example, if you ingest 100 documents with the default document persistence set and then change the ingestion configuration to remove the default setting and ingest 50 documents, then the original 100 documents will remain in the collection but the additional 50 documents ingested will not be in the collection.
Document persistence - keeping this enabled stores the ingested documents in its assigned collection. If this is disabled, the newly ingested documents will not persist in the collection. This will not affect the existing documents in the collection.